





第3回
ゲームとAI
中学数学・高校物理から始めるディジタルゲームの人工知能
AI in Video Games
Introduction to AI in Digital Games from Mathematics in Junior High School and Physics in High School
三宅 陽一郎 (株)スクウェア・エニックス
Youichiro Miyake SQUARE ENIX CO., LTD.
Keywords: autonomous, function, game, agent architecture.
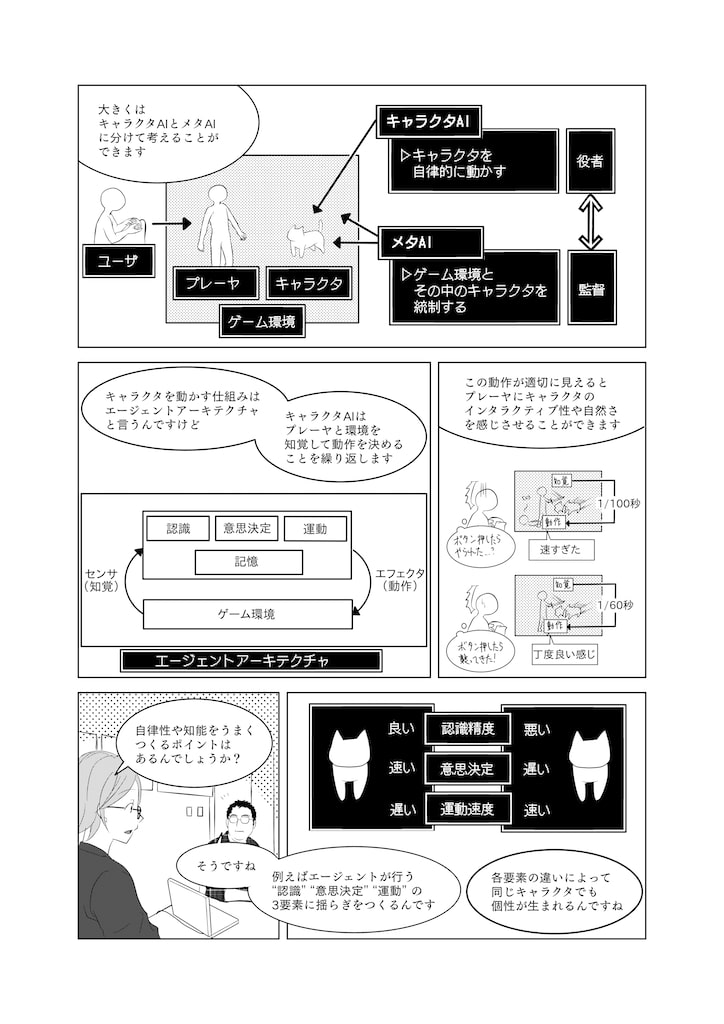
1.人工知能とは関数
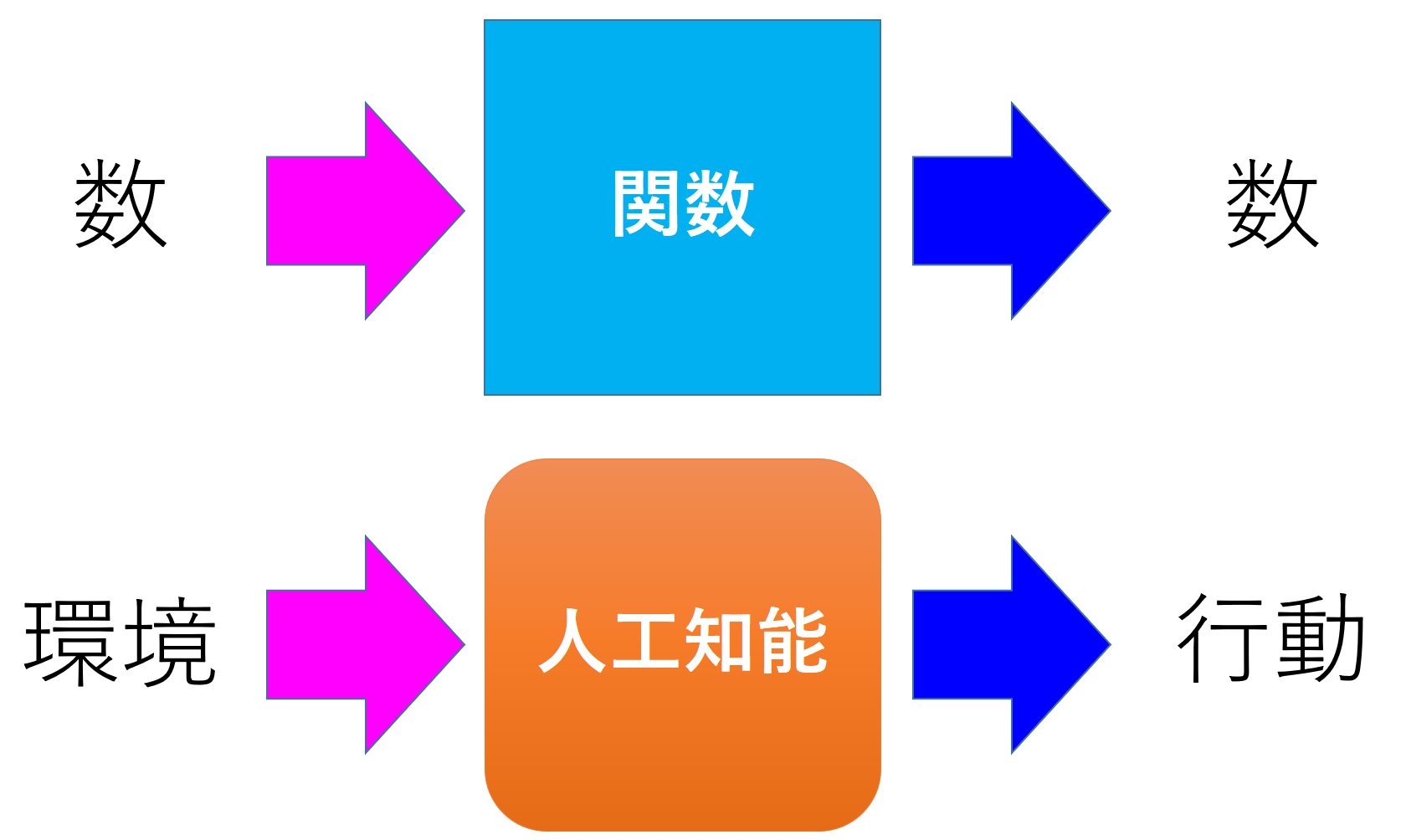
中学生になると「関数」を勉強します.例えば,1 を入れたら2,2 を入れたら4,4を入れたら8,これはつまり(f x)=2x という関数ですね.関数って一体何に役立つのだろう,と考えるのは自然です.関数そのものに興味をもつのは数学者ですが,その応用は多岐にわたり,関数は経済,物理,人工知能,あらゆる分野における基本的な言葉です.物理学はほんの400 年前に,この宇宙の法則が関数で書けることを発見しました(図1).
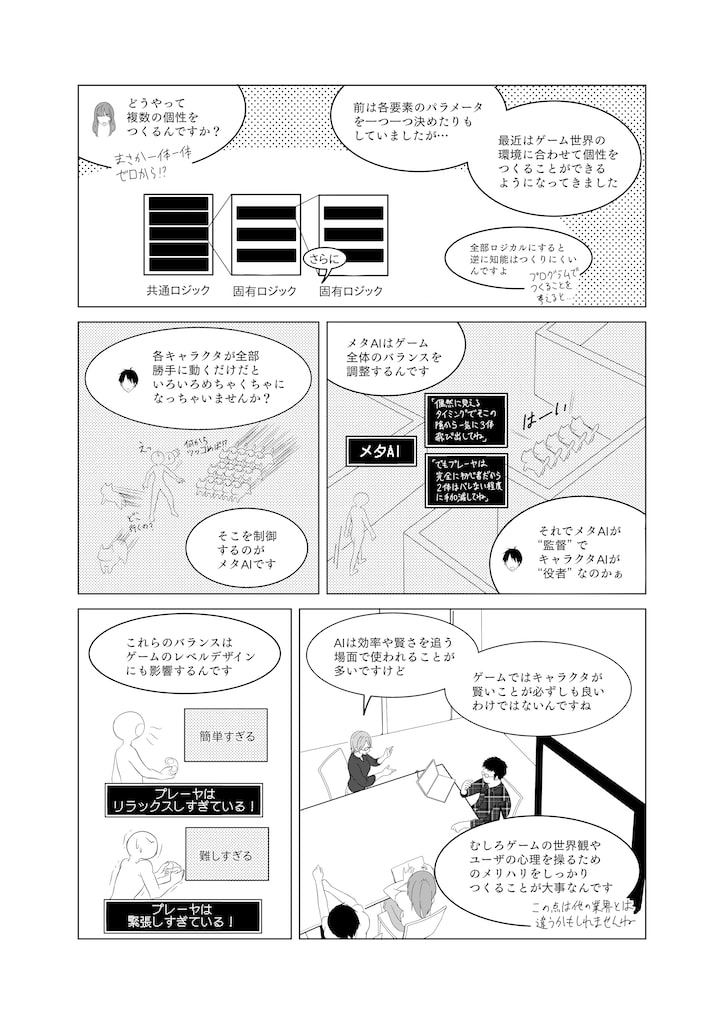
筆者の仕事はゲームの中の人工知能をつくる仕事です.ゲームの中には敵キャラクタや,仲間キャラクタなど,プレーヤ以外のたくさんのキャラクタ(Non-Player Character:NPC)がいます.その頭の中をつくる仕事です.キャラクタ自身が自分の周囲の環境を目や耳から知覚して,自分で考えて,身体を自分で動かすようにつくります.仮想ゲーム環境においては「自律型AI」(autonomous AI)といいます.例えば,「プレーヤキャラクタを見つけたら近づいて攻撃する」には,「プレーヤキャラクタを発見する」,「近づくか,隠れるかを判断する」,「(近づくことを決めたら)プレーヤに向かって走る」ことになります.これは何かに似ていませんか? そう,関数そのものですね.
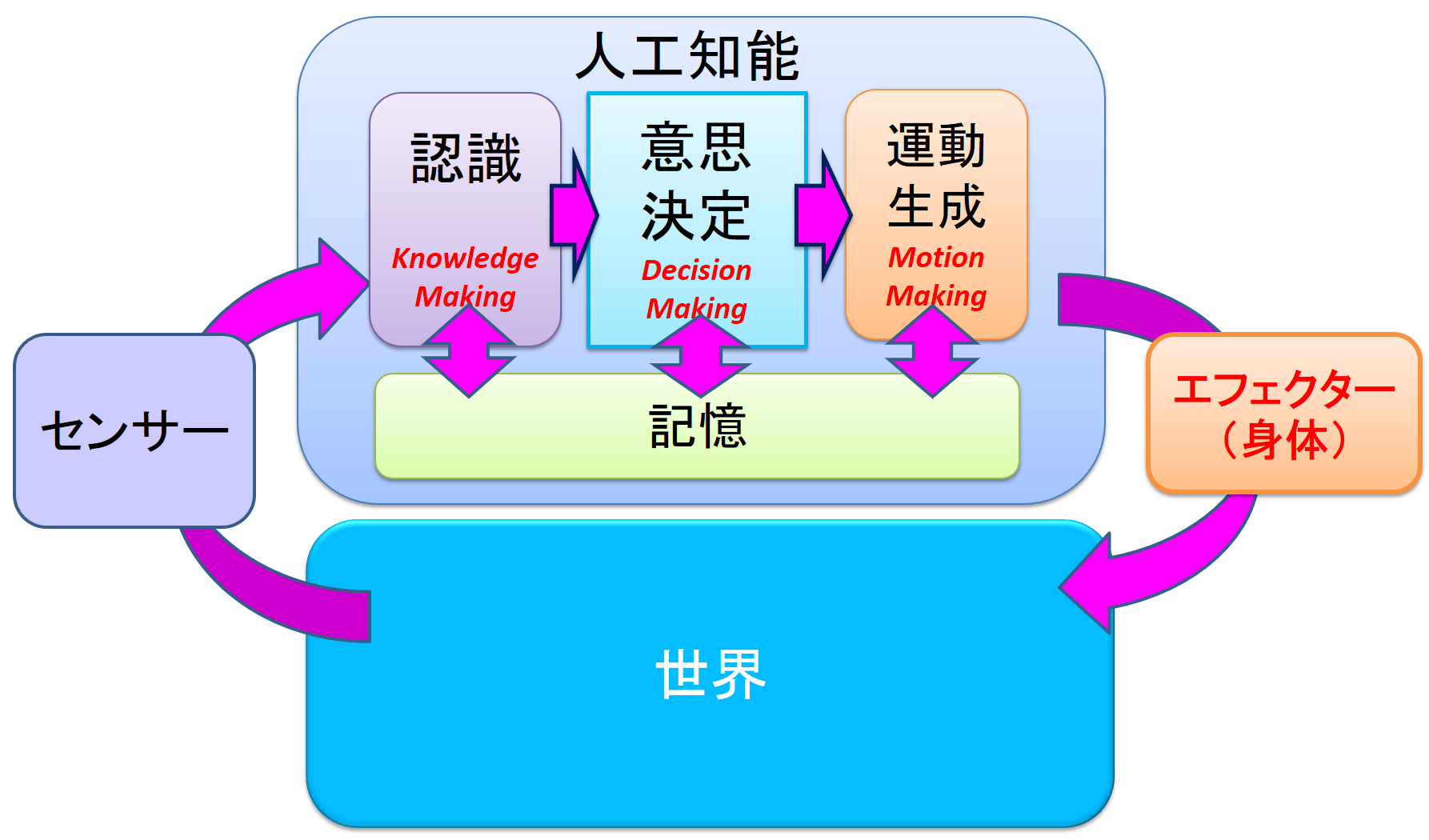
人工知能の基本は「入力して,考えて,出力する」です.この入力を受け取る部分を「センサ」(感覚),解釈する部分を「認識」,考える部分を「意思決定」,行動を形成する部分を「運動生成」,実際の身体のことを「エフェクタ」(ゲーム環境に影響を与えるもの)といいます.「関数と人工知能は同じものだ!」これはほぼ正しいことです.しかし,関数と人工知能に決定的な違いが一つあります.それは記憶がある,ということです.人工知能は環境から行動をつくっていく中で,さまざまな知識を貯めたり,学習したりします.例えば,赤いモンスターは強い,とか,緑色のモンスターは毒を吐く,とか,沼の周りは危険,などです.この蓄積する場所を「記憶」といいます.これで役者が出そろいました.
自律型AI をつくるモジュール(部品)は六つです.「センサ」,「認識」,「記憶」,「意思決定」,「運動生成」,「エフェクタ」です.このアーキテクチャ(全体の仕組み)のことを「エージェントアーキテクチャ」といいます(図2).これはロボットやキャラクタといった自律型AI に共通するアーキテクチャです.プログラムしてつくるときは,これを「モジュール化」してつくります.モジュール化とは,独立した部品としてつくって組み合わせることです.モジュール化することで,それぞれの部品をより質の高いものや,違うものにいつでも入れ替えることができるからです.
2.人工知能をつくろう
人工知能をよく理解する方法は人工知能をつくることです.「人工知能ってつくるのは大変なことじゃないの」と思われるかもしれません.しかし,ゲームの人工知能は,パソコンさえあれば,それなりにつくることができます.しかもゲームで使う数学はだいたい高校で習う数学までで大丈夫です.では,プレーヤと戦う敵キャラクタのAI をつくっていきましょう.お互い魔法攻撃(まっすぐ飛ぶ)を撃って,当たったほうが負けとします.ただし,プレーヤの魔法は9 m,敵キャラクタの魔法は7 m しか届かないとします.
2・1 センサをつくろう
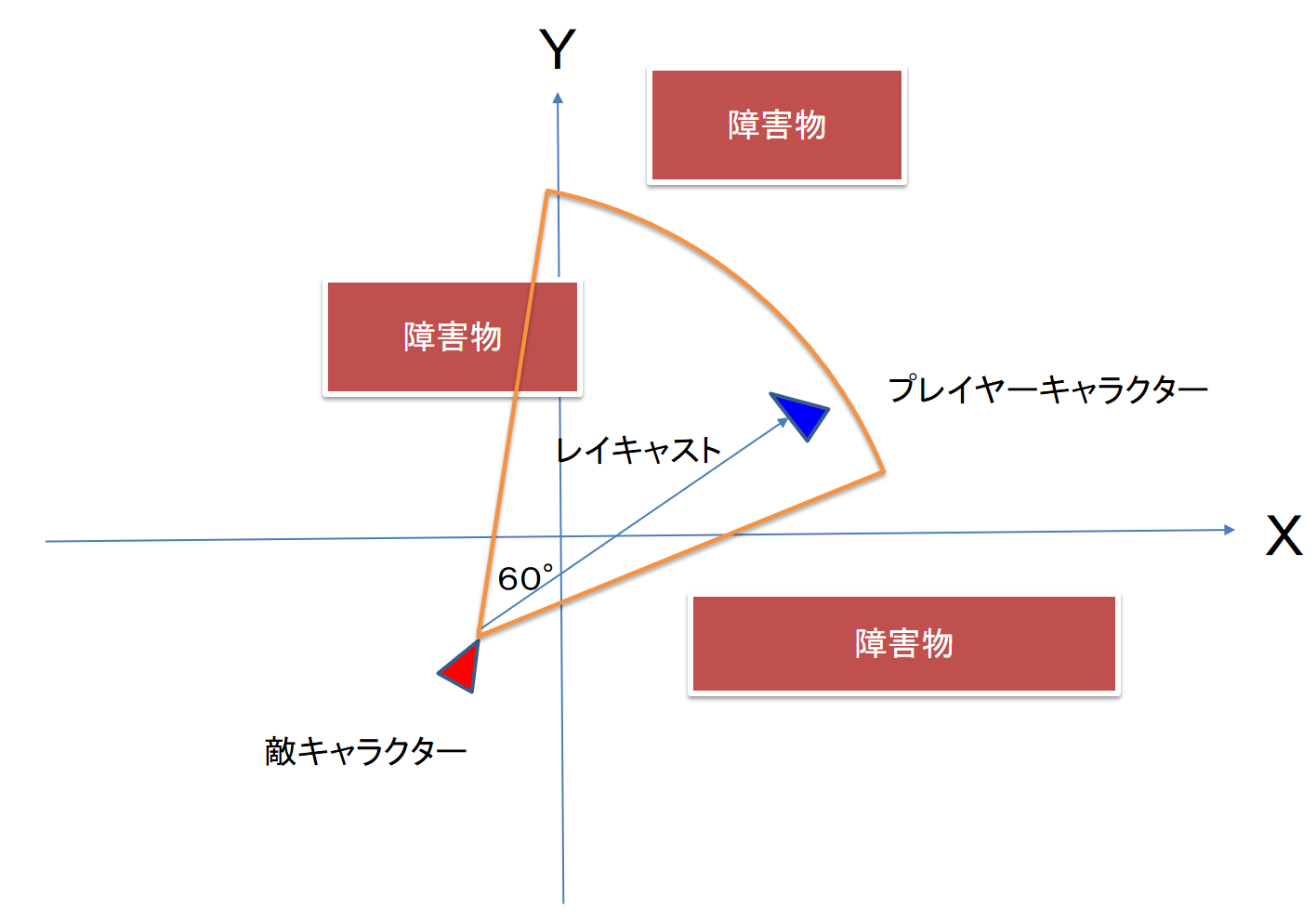
マップ上にはたくさんの障害物があります.敵キャラクタにはセンサ領域を設定します.ここに入ったら気付く可能性がある,という領域です.ここでは扇型の半径を10 m,視野角は60 度としましょう.では,プレーヤキャラクタの座標( X, Y )がこの扇型に入っている条件とは何でしょうか? これは座標幾何学の問題ですね.
さて,プレーヤがこの扇型に入ったとします.敵キャラクタから本当にプレーヤが見えているかは,障害物が邪魔をして見えていないかもしれません.そこで,敵キャラクタからプレーヤキャラクタの座標へ線を引いてみます.ゲームAI ではこれを「レイキャスティング」といいます.もし,二者を結ぶ線分が障害物と交わらなければ「見えている」,交われば「見えていない」ことにします(図3).
2・2 認識をつくろう
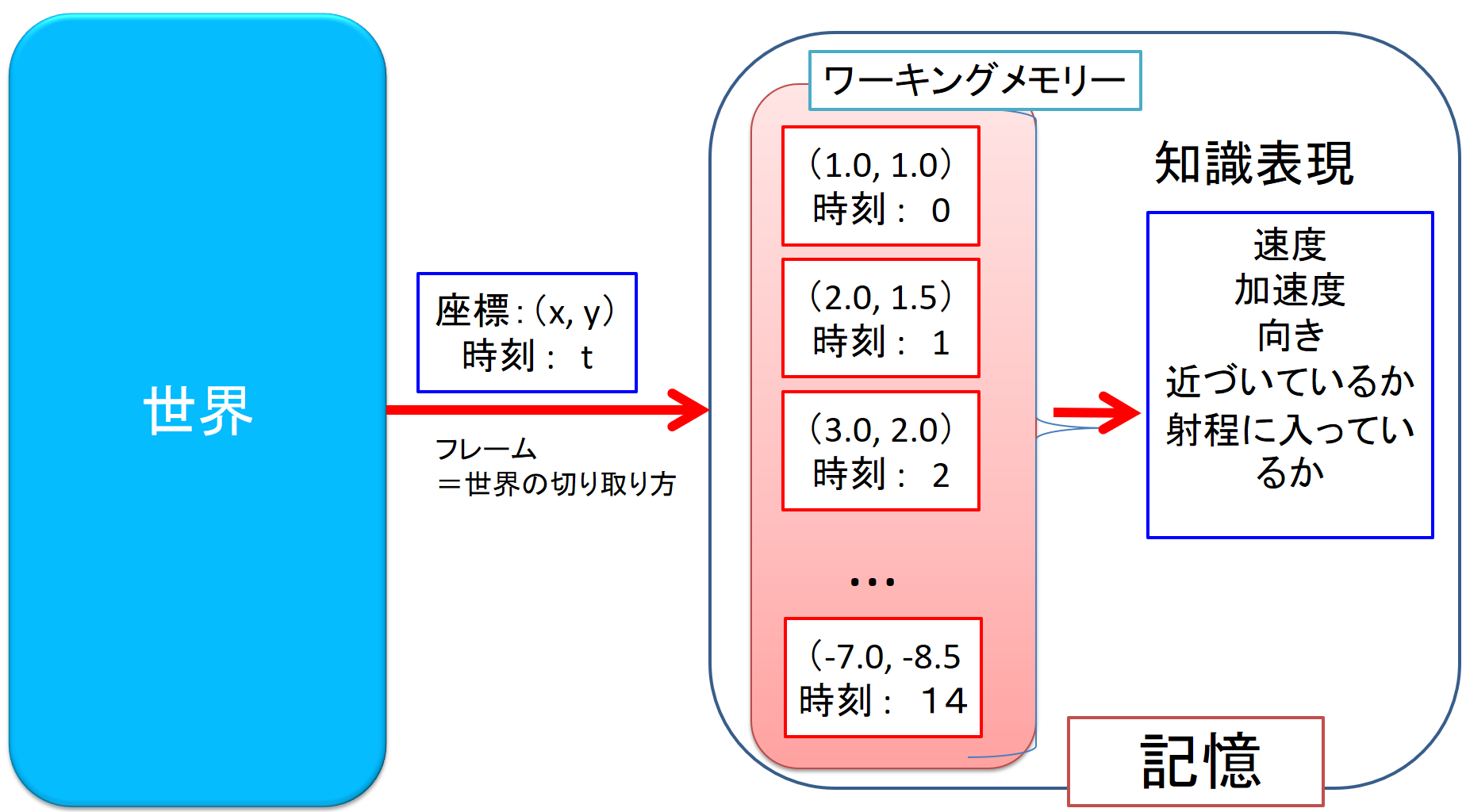
次に認識です.認識とは何か? という哲学的議論を避けるために,人工知能では「フレーム」を用意します.「フレーム」とは知識の型のことです(図4).
今回は,
フレーム:
プレーヤの座標:( x, y)
観測時刻:t
とします.「認識」では,このフレームの型の情報を各瞬間に切り取り,記憶に貯めていきます.この記憶を解析すると,プレーヤの移動の軌跡,速度と向き(ベクトル),加速度,自分に近づいて来るのか,遠ざかって行くのか,どちらともいえないか,さらに,相手が自分の射程内にいるか,自分が相手の射程内にいるかがわかります.これは高校で勉強する物理学の知識です.導出された知識もこのように形が決められています.これを「知識表現」といいます.
2・3 意思決定をつくろう
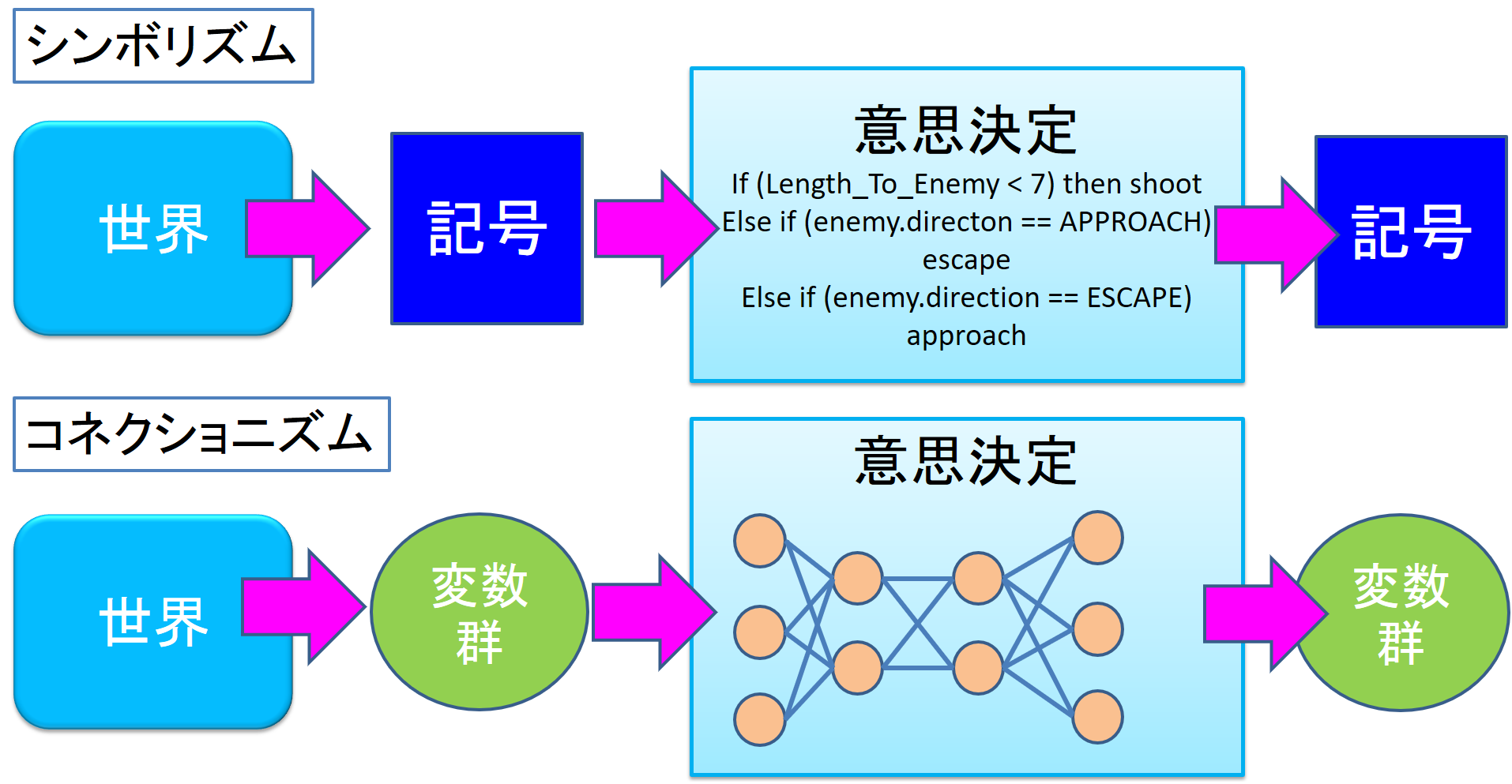
意思決定のつくり方は大きく二つあります.実はこの方法をめぐって,人工知能には二つの潮流があります.「シンボリズム」(記号主義)と「コネクショニズム」です(図5).
1)「もしプレーヤキャラクタが射程内で見えていたら」魔法を撃つ
2)1)ではなくて,「もしプレーヤキャラクタが近づいて来ていたら」逃げる
3)1)でも2)でもなく「もしプレーヤキャラクタが遠ざかっていたら」追いかける
というつくり方が考えられます.こちらは一度状況をシンボルに置き換えて規則(ルール)をつくります.このようなつくり方を記号主義(シンボリズム)といいます.
もう一つの考え方が「コネクショニズム」です.人間の脳の神経回路(ニューラルネットワーク)をシミュレーションする形式です.人工ニューラルネットワーク(Artificial Neural Network)が正式な名前ですが,通常単に「ニューラルネットワーク」と呼ばれています.近年では、複雑なニューラルネットワークが深層学習として,注目を浴びています.知識の形を気にせずに,入力にデータを入れて,出力の出方で行動を決めます.この形式でキャラクタを動かすためには,「こんな入力のときにはこういう行動をする」というパターンを学習していく必要があります.具体的には,神経細胞(ニューロン)どうしの結合の強さを徐々に変えていきます.ここでは説明を省きます.ニューラルネットワークの逆伝播法を勉強するには,高校生の微積分の知識があれば十分です.直観的には中学校の数学まででも十分です.
ゲーム開発では主に「シンボリズム」の手法を使いますが,「コネクショニズム」もときどきですが使う場合があります.特に開発を支援する人工知能では「コネクショニズム」がよく使われます.
2・4 行動をつくろう
意思決定で「近づく」を決めたとします.そこから具体的な身体行動を生成する必要があります.ここではプレーヤに向かってある速度で移動することが必要となります.向きを決めて,速度を決めて,自分の身体(エフェクタ)に送り込みます.すると,敵キャラクタの身体が動き出します.
2・5 結 果
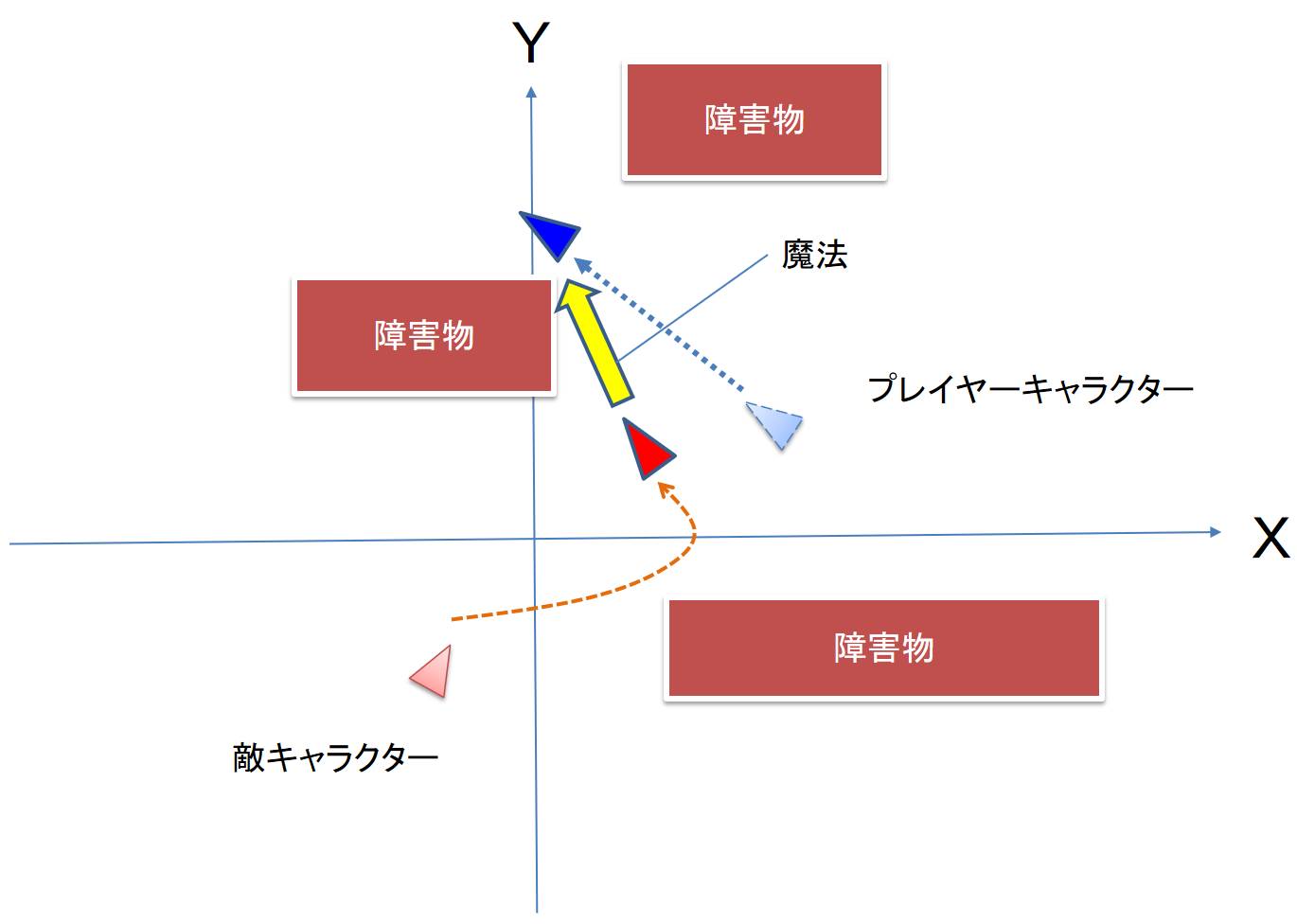
さて,どういうふうに動くか想像してみましょう.いろいろな状況もありますので,今回は一つの例です.プレーヤが動くと,その方向に向かって敵キャラクタも動きますので,敵キャラクタはプレーヤを追う形になります.そして,射程内に入ったところで,魔法を撃ちます(図6).
3.ゲームと揺らぎ
ゲームでは「揺らぎ」が大切です.揺らぎとは,正確さを少しずらしてあげることです.現実世界はノイズだらけで,おかげでAI を動かすことが大変困難です.しかしゲーム環境にはノイズがありません.ノイズがないことはAI を動かしやすいことではありますが,毎回同じようにゲームが展開するので飽きてしまう,という弊害があります.そこで,乱数を入れることで敵キャラクタに「揺らぎ」をもたらします.具体的には,認識の部分に揺らぎを入れます.2 章で説明した方法では,どんな場合も正確にプレーヤキャラクタの位置がわかってしまいます.でも敵キャラクタにはどんくさいキャラクタや,近眼のキャラクタもいるかもしれません.そこで,プレーヤキャラクタを見つけたとしても,その認識する座標に少し揺らぎを入れてやるのです.(3.7, 3.8)が正確な座標であれば,(4.0, 3.6),(3.2, 4.1)など0.5 幅の乱数を足し引きしてずらしてやります.そうすると,間違った方向や,誤った場所に魔法を撃ち込むなどが起こります.それは駄目なのでは? と思うかもしれませんが,そのほうが人間的です.100%正確な射撃でないほうが生き物らしいですから,間違ったほうがよい場合もあります.もちろん,どれぐらい間違うか,というのは,乱数の幅を,今は0.5 としていますが,減らしたり,増やしたりすることで,調整することができます.
4.エンタテイメントのAI
筆者の専門分野は人を楽しませるためのAI です.映画では役者と映画監督がいます.役者が演技をして,監督が指示を出します.役者は自分の周りしか見えませんが,監督は全体を見渡して指示を与えます.ディジタルゲームもプレーヤ以外のキャラクタ(Non-PlayerCharacter)は役者であり,それに指示を出すAI が必要です.これを「メタAI」といいます.
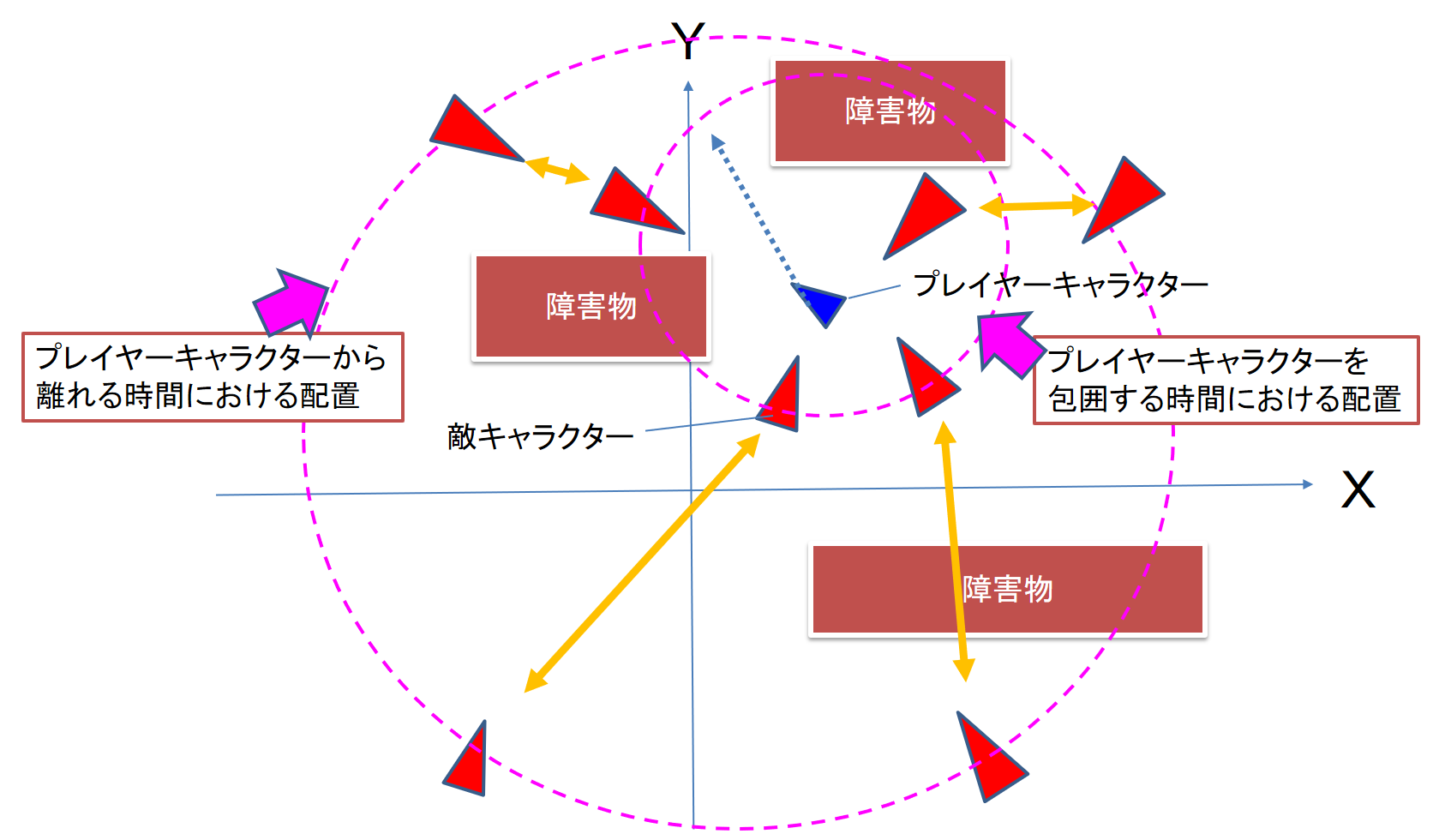
3 章まででせっかく敵キャラクタをつくったので,4 体の敵キャラクタにプレーヤを追いかけさせてみましょう.しかし,普通に追いかけさせたらプレーヤは魔法を撃ち込まれて終わりでしょう.そんなゲームは面白くありません.ゲームの面白さとは何か? それは緩急にあります.緊張した状態から緩和した状態になること,劣勢から優勢になることです.そこで,メタAI によって三つの指示を4 体のキャラクタにしておくことにします.
(1)プレーヤキャラクタに対する魔法は外して撃つこと
(2)プレーヤキャラクタを包囲しても一方向は逃げるように開けておくこと
(3)プレーヤを包囲する時間と,それぞれが離散する時間を一定時間ごとに区切ること
このような規則をメタAI が敵キャラクタにもたせることで,ゲームは一定のリズムをもつようになります.これがメタAI の力です(図7).
5.エンタテイメントのAI
ディジタルゲームAI を一通り見てきました.メタAI の上記の原理は実は「パックマン」(ナムコ,1980 年)のアルゴリズムを参考にしています.本誌(人工知能)2019 年1 月号(Vol. 34, No.1, pp. 86-99)では,パックマンのゲームデザイナ岩谷 徹氏のインタビューとパックマンの仕様書が全公開されています.
ディジタルゲームは1970 年代の中期から始まりました.ディジタルゲームAI 技術はその後でゆっくりと立ち上がり,1995 年前後のゲームの3D 化で大きな変化を受けます.それまで俯瞰的に動かされていたキャラクタは,複雑な環境の中で,自分自身で考えて動くことが強いられるようになります.これが「キャラクタAI」の自律化です.
現実空間で自律的に活動するロボットのもつAI 技術は,仮想空間でキャラクタのもつ自律的AI 技術と,とても似ています.キャラクタAI の技術は,この20 年間,ロボティクスの技術を吸収しながら発展してきました.その基本は1 〜3 章に書いたとおりです.しかし,キャラクタが独立に自律的にそれぞれの判断に沿って動くことによって,ゲーム状況にまとまりがなくなってしまいました.そこで,ゲームの流れに沿った前提的な動作とするために,「メタAI」が新しい形で導入されることになりました.パックマンの時代では,パックマン達はゲームシステムに操られていましたが,現代のキャラクタは自律的に動きます.しかし,ゲームはエンタテイメントですから,ユーザを楽しませなければなりません.メタAI は,ゲーム全体をコントロールすることで,ゲームがユーザにとってエキサイティングになるように調整するのです.
6.人工知能をつくることは人間を知ること
エンタテイメントにおいて,人工知能をつくることは,人間を知ることです.どうすれば,ユーザを楽しませることができるか,このように行動すればユーザはこう感じるはずだ,ということを想定します.また,人工知能をつくる最大のリファレンスは人間であり,そして自分自身でもあります.文科系とか理科系という区別を超えたところに,AI という分野はあります.AI をつくることは,科学であり,哲学であり,工学であり,それらが交錯する場所にあります.