| |
![[What's AI]](whats_AI_icon.gif) 人工知能の話題
人工知能の話題
 TDギャモン
(TD-Gammon)
TDギャモン
(TD-Gammon)
TDギャモン (TD-Gammon)(注1)は,G.Tesauroが開発したシステムで,バックギャモンというゲームの対戦を行います.強化学習(注2)という方法で自分でいろいろな手を試して強くなることができます.
![]()
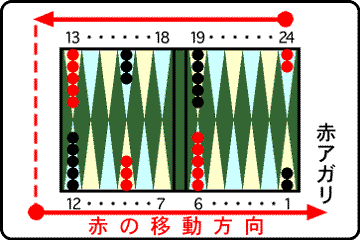 はじめに,バックギャモンのルールについてごく簡単に説明します.このゲームは右の図の盤上で,赤と黒の丸いコマを受け持つ二人が対戦します.コマをおくマスは図の水色と黄色の部分です.ルールは「すごろく」と似ています.図のようにお互い15個ずつコマを並べた状態から始めます.2個のサイコロの目に応じて交互にコマを進めて,全部のコマをアガリまで先に動かした方が勝ちです.赤は反時計回り(24→1の方向)に,黒は時計回り(1→24の方向)にコマを動かします.
はじめに,バックギャモンのルールについてごく簡単に説明します.このゲームは右の図の盤上で,赤と黒の丸いコマを受け持つ二人が対戦します.コマをおくマスは図の水色と黄色の部分です.ルールは「すごろく」と似ています.図のようにお互い15個ずつコマを並べた状態から始めます.2個のサイコロの目に応じて交互にコマを進めて,全部のコマをアガリまで先に動かした方が勝ちです.赤は反時計回り(24→1の方向)に,黒は時計回り(1→24の方向)にコマを動かします.
その他,相手をとばしてしまうヒットや,相手の進行を妨害できるブロックといったルールがあり,駆け引きが必要です.他にもいろいろなルールがありますが,TDギャモンの説明には関係ないのでここでは省略します.(詳細なルールの説明は日本バックギャモン協会にあります)
![]()
TDギャモンに話をもどしましょう.このシステムの特徴は,自分同士で対戦を繰り返し(注3),その経験から学習して強くなることです.例えば,赤が黒に負けると,負けたときのコマの動かし方を検討し,負けたときと同じようなコマの動かし方をしないようにします.TDギャモンは,こうした試合を150万回ほど繰り返して,人間のトッププレーヤーと互角に渡り合えるようになりました.
![]()
ここで,一つ問題があります.普通の人工知能の学習方法では,コマを動すごとに,その動かし方が良かったかどうかを,その時にすぐ教えてもらわないと学習できません.ところが,試合では,お互いに何度もコマを動かしてゲームが終わったあとに勝敗が分かるだけです.
そこで,TDギャモンは強化学習という方法を使います.強化学習は,コマを動かしたときにすぐには結果が分からず,ずっと後に結果がわかる状況でも学習できる便利な方法です.具体的な方法としては,R.S.SuttonのTD(λ)(ティー・ディー・ラムダ)や,C.J.C.H.WatkinsのQ学習などがあります.
![]()
TDギャモンは,コマの配置や赤番・黒番といった状況が異なっている各場面について,その場面で自分の勝算がどれくらいあるかということを学習します.この学習結果に基づき,勝算ができるだけ大きくなる場面になるようにコマを動かします.強化学習は,試合の結果から勝算の大きさを学習するために利用されます.それでは,もう少し詳しく見てみましょう.
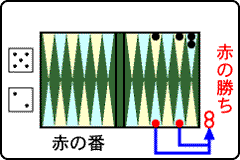 右の図の場面は,赤の番でコマを全てアガリに動かして試合に勝ちました.このことから,図のような場面は勝利の一歩手前であるということが分かりました.ですので,図の場面について,現在,想定している勝算を少し増やします.
右の図の場面は,赤の番でコマを全てアガリに動かして試合に勝ちました.このことから,図のような場面は勝利の一歩手前であるということが分かりました.ですので,図の場面について,現在,想定している勝算を少し増やします.
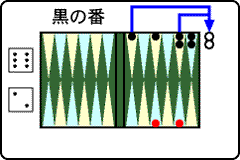 右の図は,前の図の一つ前の黒番の場面です.この配置から2回コマを動かして赤が勝ったので,この場面での赤の勝算を,前の図の場面と同じように増やします.このように,強化学習では,勝った場面からどんどん前にたどった場面の勝算も増やすようにすることで,コマを動かすたびに教えてもらわなくても,いろいろな場面での勝算を学習できます.
右の図は,前の図の一つ前の黒番の場面です.この配置から2回コマを動かして赤が勝ったので,この場面での赤の勝算を,前の図の場面と同じように増やします.このように,強化学習では,勝った場面からどんどん前にたどった場面の勝算も増やすようにすることで,コマを動かすたびに教えてもらわなくても,いろいろな場面での勝算を学習できます.
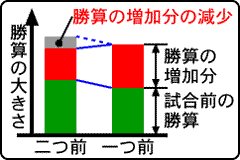 さらに,もう一つ工夫があります.勝敗が決まる一つ手前と二つ手前のどちらの場面でも勝算を増やすのですが,その増加分は一つ前の方が二つ前より多くなるようにします.
さらに,もう一つ工夫があります.勝敗が決まる一つ手前と二つ手前のどちらの場面でも勝算を増やすのですが,その増加分は一つ前の方が二つ前より多くなるようにします.
右のグラフを見てください.緑の部分が試合前の各場面の勝算,赤い部分が今回,増やした勝算になります.つまり,緑に赤を加えた部分が試合後に学習された各場面の勝算です.赤い部分の勝算の増加分に注目すると,一つ前の増加分より,二つ前の増加分はグレーの部分だけ減っています.
このように前の場面になるほど,勝算の増加分を少なくするのは,勝敗が決まる場面に近い方が,勝敗がより確実になっているからです.つまり,前の場面ほど勝負が決まるまでに,相手が予期しないコマの動かし方をしたり,起死回生のサイコロの目が出たりする機会が増えるためです.
![]()
このようにして,試合中で経験した場面について勝算を学習して,次の試合にその成果を生かします.試合では,サイコロの目がでたあと,ルールで許されているあらゆるコマの動かし方を仮にしてみて,動かしたあとの場面の勝算を調べます.そして,勝算がいちばん大きくなった動かし方を選んで,その動かし方を自分の手とします.このように,試合と学習を繰り返して,どんどん強くなることができます.
![]()
この強化学習は,他にも,ロボットなどの機械の微妙な制御を試行錯誤によって調整するなどの目的で活発な研究がなされています.
![]()
注1:G.Tesauro“Practical Issues in Temporal Difference Learning”Machine Learning,vol.8,pp.257-277 (1992)
注2:R.S.Sutton,A.G.Barto “Reinforcement
Learning”MIT Press (1998) ISBN 0-262-19398-1
R.S.Sutton,A.G.Barto,三上貞芳(訳),皆川雅章(訳) “強化学習”森北出版 (2000) ISBN 4-627-82661-3
![]()
リチャード・S・サットン:TD(λ)アルゴリズムなど,強化学習の理論的基盤の研究で知られています.
注3:2016年に囲碁において人間のトッププロに勝利した Alpha GO でもこの自己対戦にの枠組みが重要な役割をはたしました.
| |
人工知能学会の問い合わせ先一覧 |